Soil carbon models, process realism, and AI
A commentary prompted by a new paper by Zhang and Viscarra Rossel (2026) in Geoderma
For many years, soil carbon models succeeded by remaining simple enough to work with limited data. They represented the soil system using a few conceptual pools that decayed at fixed rates (so-called first-order decay) and required only modest inputs, such as total organic carbon, clay content, and temperature. Much of the biology and chemistry was folded into a handful of effective parameters. This simplicity made models like CENTURY and Roth-C practical and influential, especially in large-scale land and Earth system modelling. However, it also meant that many important processes were represented only implicitly.
That is now changing. A new generation of soil carbon and biogeochemical models seeks to represent the soil system more explicitly and in more measurable terms. Instead of treating decomposition and stabilisation as black-box processes with effective turnover rates, these models aim to represent microbial activity, mineral association, aggregation, sorption, saturation, and other mechanisms that help determine whether carbon is lost, recycled, or retained in soil. Models such as Millennial v2, MIMICS, and MEMS 2 are part of that shift.
However, greater realism comes at a price. More realistic models require more information: better initialisation, better environmental forcing, more rigorous calibration, and better ways to test whether simulated pools correspond to those in real soils. In our recent work with Millennial v2 across the Australian rangelands, we found that even with a next-generation model, predictions remained uncertain and depended strongly on how the model was constrained.
What we observed is not unique to Millennial v2 or to Australia. It reflects a broader pattern in biogeochemical modelling: process realism does not automatically produce predictive certainty. If anything, as models become more explicit, their uncertainties become more visible. Older models could function with sparse data partly because so many processes were folded into a few aggregated terms. Newer models expose more of the underlying structure, but in doing so they create much greater demands for observation and inference.
This is why the current wave of technological change matters. Today, we have far richer streams of information than the modellers who built the first generation of soil carbon models could have imagined. Remote sensing can provide spatially explicit information on productivity, vegetation dynamics, land cover, and environmental forcing. Climate reanalysis products can improve estimates of soil moisture and temperature through time. Proximal sensing and new laboratory methods are making it increasingly feasible to measure soil physical, chemical, and biological properties at greater density and lower cost. Together, these technologies can help initialise models, constrain state variables, and test predictions against measurable aspects of the soil system.
In our study, better environmental inputs and measurable carbon fractions were central to improving model performance. The model was strengthened by site-specific data, updated estimates of maximum sorption capacity, and a hierarchical parameter calibration that accounted for spatial heterogeneity. These improvements were specific to our setting, but the principle is general: the future of process-based soil carbon modelling lies not only in better equations, but in linking those equations much more tightly to observations.
So, where does AI fit into this picture? In a recent commentary, Alexandrov (2025) asked whether neural networks could replace process-based models in ecological modelling and concluded that they would not, because process-based models provide conservation principles and causal structures that purely data-driven approaches often lack. That is likely to be true for soil biogeochemistry as well. AI is more likely to enable and surround process-based models than to replace them. Process-based models provide structure and interpretability; AI is especially useful when complexity becomes too large, nonlinear, or too data-rich to handle efficiently.
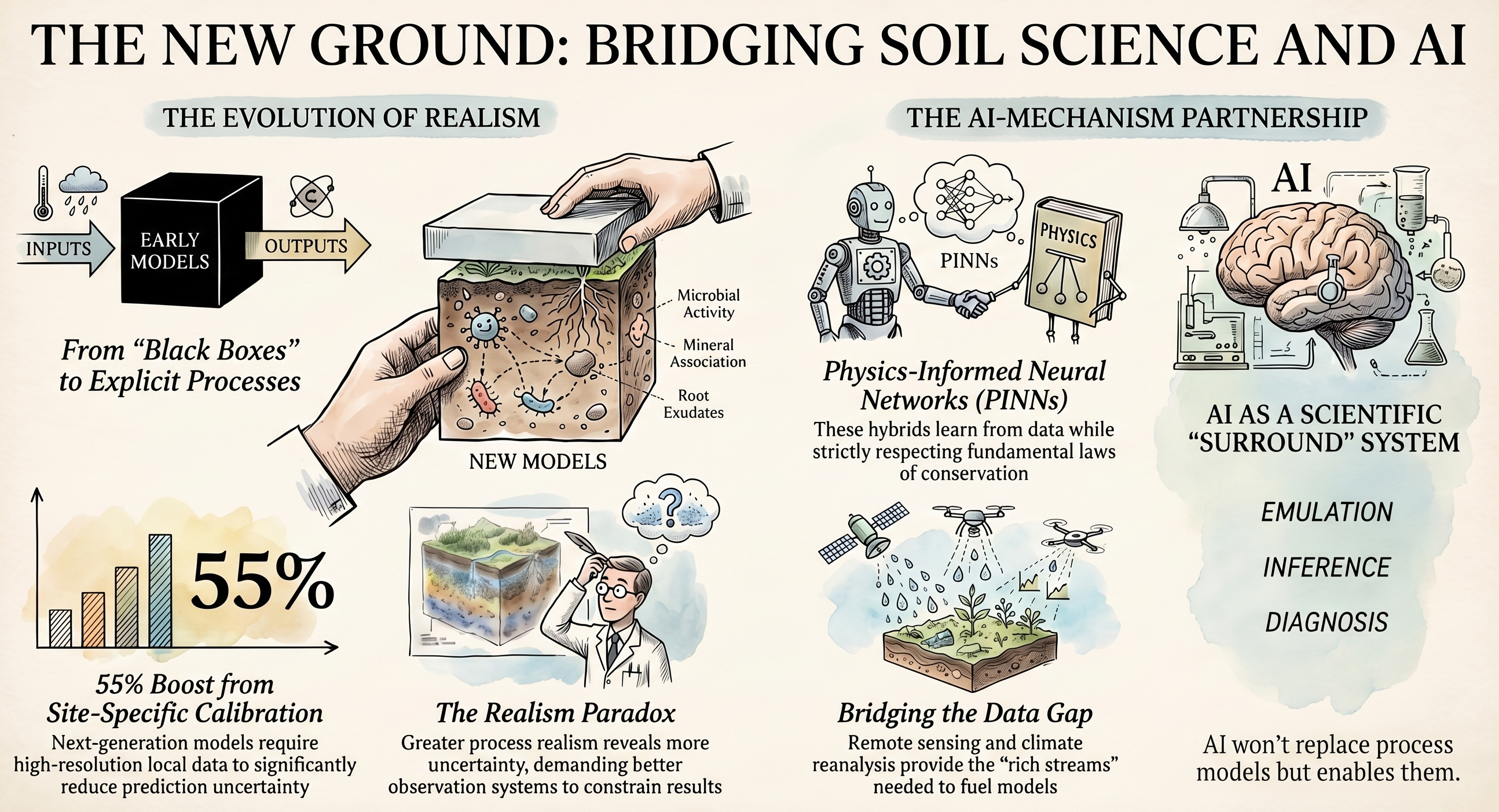
AI can play at least four distinct roles here. Emulation. Machine-learning surrogates can approximate computationally intensive process models, making it feasible to explore uncertainty, compare scenarios, and embed process models within broader decision systems. Inference. AI can help estimate difficult parameters, recover hidden states, and connect sparse measurements to quantities that matter for modelling but are rarely observed directly. This is especially relevant for next-generation soil carbon models, where parameters govern microbial activity, sorption, aggregation, and environmental response. The challenge is often not running the model, but learning how its parameters vary across soils, climates, and ecosystems. Diagnosis. Explainable AI can show which predictors drive performance, where observations and simulations diverge, and which processes may be missing or misrepresented. In that sense, AI is not just a predictive tool; it can help us ask better scientific questions about why a model works in one setting and fails in another. Data integration. Environmental science increasingly depends on combining field measurements, laboratory data, sensor streams, reanalysis products, and satellite observations. AI methods are well suited to linking these sources, filling gaps, downscaling coarse information, and generating inputs that are more spatially and temporally relevant to the process model.
One approach deserves closer attention, physics-informed neural networks, or more broadly process-informed neural networks (PINNs). Their appeal is that they do not treat data and equations as competing alternatives. Instead, they learn from data while still respecting known constraints, such as differential equations or conservation laws. For biogeochemical modelling, that makes them promising where we have at least a partial understanding of the governing processes but need a more flexible way to estimate hidden states, parameters, or corrections to imperfect model structure.
But PINNs are not the whole answer. They are most useful when the underlying equations are already informative and the main challenge is combining them with data. Many environmental systems are more difficult than that. Soil and biogeochemical processes are multiscale, heterogeneous, and still only partly understood. When scientific uncertainty stems from missing mechanisms or incomplete theory, no neural architecture can simply conjure that understanding into existence. As Alexandrov (2025) argues, a neural network may fit closely within its training range and still fail badly when asked to predict beyond it. That matters for soil carbon under a changing climate, where we often need to make predictions outside the conditions we have already observed.
A different use of AI sits at the workflow level. Agentic systems are not new biogeochemical models. They are tools for coordinating complex tasks, such as assembling data, selecting and calibrating models, comparing scenarios, and documenting provenance. That could make them useful assistants as modelling increasingly depends on linked data products, multiple sensors, and hybrid computational methods.
Even so, agentic AI should be understood as part of the modelling workflow, not as a substitute for scientific reasoning. It may help researchers manage complexity, but it still depends on the quality of the data, the design of the model, and the validity of the assumptions built into the system. Weak science cannot be rescued by better orchestration.
Will AI replace biogeochemical models? Probably not. A more likely future is that AI changes the role of the biogeochemical model itself. Rather than acting as a stand-alone predictor, the process-based model becomes part of a larger scientific system that combines improved measurements and sensing, machine-learning emulators and inference methods, and perhaps agentic tools to manage the workflow. In that system, the process model still matters because it provides structure, interpretability, and scientific discipline.
This is the larger message of next-generation modelling. Older models succeeded partly because they made the problem manageable when data were scarce. Newer models are more ambitious because they try to represent more of the real processes that drive environmental change. But that ambition only pays off if it is matched by equally ambitious observation systems and smarter computational tools. The challenge is no longer simply to build more complex models; it is to build modelling frameworks that can learn from new data without losing touch with mechanism, constraint, and explanation.
If we can achieve that balance, the rewards are substantial. Together, they can sharpen predictions of soil carbon change and deepen our understanding of the biogeochemical cycles that support ecosystems, agriculture, and climate stability. The future is unlikely to belong to either approach alone, but to combinations that allow us to observe more, infer better, and understand more clearly how soil and the environment work.
References
Zhang, M. and Viscarra Rossel, R.A. (2026). Enhanced predictions of measurable soil carbon pools in the Australian rangelands with the Millennial v2 model. Geoderma, 469, 117811. https://doi.org/10.1016/j.geoderma.2026.117811
Alexandrov, G.A. (2025). When does artificial intelligence replace process-based models in ecological modelling? Ecological Modelling, 499, 110923. https://doi.org/10.1016/j.ecolmodel.2024.110923